今回はWebスクレイピングの処理速度を高速化する方法について紹介します。
著者は本サイトにWebスクレイピングツールを実装しています。
しかし、実装当初はページの読み込みに6秒もかかってしまい、とにかくレスポンスが遅い状態でした。
そこでツールを改良し、表示速度を0.5秒まで高速化させることができたので、今回はその方法について記事にしました。
前提: Webスクレイピングの手順
今回は以下の手順を行い、9つのサイトから同時にWebスクレイピングを行います。
Djangoが条件に入っていますが、こちらを利用しない方法についても紹介しています。
- requestsでHTMLをダウンロードする。
- BeatifulSoupでHTMLの情報を解析する。
- Djangoでスクレイピングの結果を表示する。
Webスクレイピングの速度を高速化する方法
Webスクレイピングの速度を高速化する方法は2つあります。
1. マルチスレッドでrequestsを実行する方法
2. あらかじめスクレイピングした情報を表示する方法
マルチスレッドでrequestsを実行する方法
この方法を利用すると、スクレイピングするサイトが多い場合は簡単に処理速度が向上します。
理由は単純で、一件ずつサイトからHTMLをダウンロードするより、並列で同時にダウンロードした方が処理効率が良いからです。
実装も簡単なので、ひとまずこちらの方法で満足のいく速度がでるか試してみると良いかもしれません。
余談ですが、Beautiful Soupを並列化してもパフォーマンスにあまり変化がなかったため、そちらの紹介については割愛しています。
※並列化前: 0.9秒 → 並列化後 : 0.85秒
あらかじめスクレイピングした情報を表示する方法
この方法はスクレイピングが遅いなら最初から終わらせておけばいいじゃない、といった方法です。
Djangoのライブラリを使用して、数時間おきにスクレイピングを実行し、その情報をDBに格納します。
ユーザーから要求があった場合は、DBから情報を取得するだけなので表示は高速です。
更新頻度の低いサイトに対してスクレイピングを定期実行する場合はこの方法がベターだと思います。
なぜならスクレイピングをする側もされる側もサーバー負荷を抑えられるからです。
ただ、Djangoありきの方法なのでお手軽さがいまいちなのが欠点です。
次項以降では、これらの実装方法について順番にご紹介します。
1 . マルチスレッドでrequestsを実行する方法
PythonのThreadPoolExecutorというライブラリを使用すると、requestsを並列で処理できるようになります。
ThreadPoolExecutorは標準パッケージであるためインストールの必要はありません。
始めにrequestsを実行するURLを定義します。
今回は下記9サイトに対してrequestsを行います。
urls = [
'https://audiobook.jp/ranking/product-total',
'https://japan.cnet.com',
'https://codezine.jp',
'https://minkabu.jp/news/search?category=popular_recently',
'https://business.nikkei.com',
'https://xtrend.nikkei.com',
'https://president.jp',
'https://jp.techcrunch.com/popular/',
'http://www.tokyoipo.com/'
]
試しにこれらのサイトに対し、シングルスレッドでrequestsを行なってみます。
※ 上記 urls のリストを for文より前に記述してください。
import requests
import time
t1 = time.time() # 処理前の時刻
results = []
for url in urls:
r = requests.get(url)
results.append(r)
t2 = time.time() # 処理後の時刻
elapsed_time = t2-t1
print(results)
print(f"経過時間:{elapsed_time}")
結果
[<Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>]
経過時間:2.328315019607544
シングルスレッドでの処理速度はだいたい2.3秒くらいです。
次にマルチスレッディングでrequestsを行なってみます。
from concurrent.futures import ThreadPoolExecutor
import requests
import time
t1 = time.time() # 処理前の時刻
with ThreadPoolExecutor(9) as executor:
results = list(executor.map(requests.get, urls))
t2 = time.time() # 処理後の時刻
elapsed_time = t2-t1
print(results)
print(f"経過時間:{elapsed_time}")
結果
[<Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>]
経過時間:0.6122088432312012
マルチスレッドでの処理速度は約0.6秒となりました。
満足のいく速度です。
解説
with ThreadPoolExecutor(9) as executor:
ここで、ThreadPoolExecutorの設定を行なっています。
ThreadPoolExecutorの引数 9 は非同期実行を行うスレッドの個数を指定しています。
None か指定されない場合のデフォルト値はマシンのプロセッサの数に 5 を掛けたものになります。参考
as executorの部分はThreadPoolExecutorの名前をexecutorに変換(別名に変更)しています。
results = list(executor.map(requests.get, urls))
上記のexecutor.map(requests.get, urls)がマルチスレッド処理を実行しているところです。
map(requests.get, urls)でurlsの要素の数だけrequests.getを実行しています。
それをexecutorで並列処理しています。
また、実行結果のresultsには、リスト型でrequestsの取得結果が格納されます。
よって、results[0].textのように指定すればBeautifulSoupで解析を行えます。
使用例:
soup = BeautifulSoup(results[0].text, "html.parser", from_encoding="utf-8")
マルチスレッドの方法については、こちらのサイトを参考にさせて頂きました。
https://ymgsapo.com/2019/08/11/multithreading-webscrape/
2 . あらかじめスクレイピングした情報を表示する方法
こちらは、スクレイピングの定期実行結果をDBに格納し、その情報をWebページに表示させる方法です。
以降の手順はDjangoを利用することが前提です。
Django環境について
Django環境がないという方については、Docker-Composeを利用した環境の準備手順をこちらの記事に記載していますので、もしよければご利用ください。
【Docker Compose】 Nginx - Django - MySQL の検証環境を作成
Dockerまで手を出すのはちょっと...でもDjangoを勉強してみたいという方には、こちらの書籍がわかりやすくておすすめです。

あらかじめスクレイピングした情報を表示する方法
本サイトのこちらに実装したもですが、改善なしだと次のような速度でした。
検証にはChrome DevToolsを利用しています。
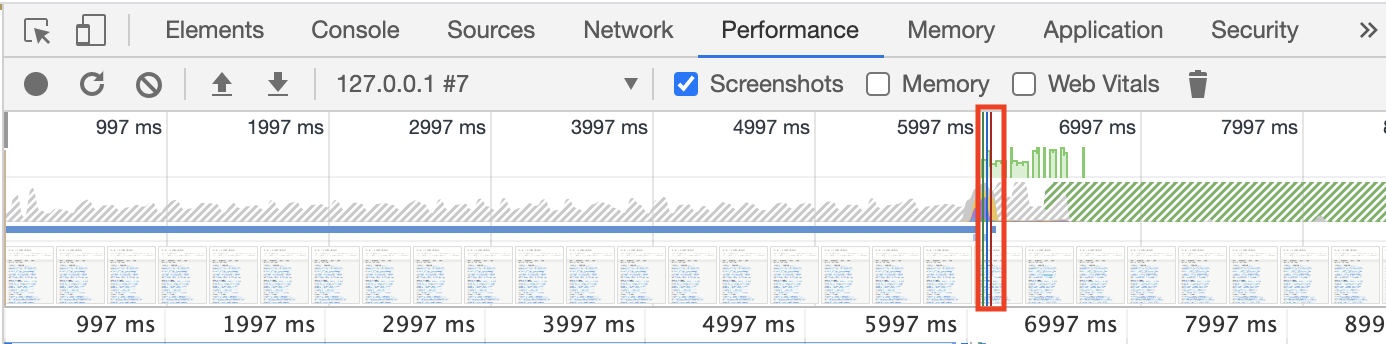
縦の赤線箇所がページの表示された時間です。
だいたい表示に6秒くらいかかっています。遅い...
こちらが1秒以内になるよう改修していきます。
DBの作成
models.pyに新しいテーブルを定義します。
class ScrapingData(models.Model):
"""スクレイピングの結果を格納するテーブル"""
sc_name = models.CharField('スクレイピング対象', max_length=50, default='')
scraping_data = models.TextField('スクレイピングの結果を格納')
update_at = models.DateTimeField('更新日', default=timezone.now)
def __str__(self):
datetime_now = self.update_at + datetime.timedelta(hours=9)
datetime_now = datetime_now.strftime("%Y/%m/%d %H:%M:%S")
return f'{self.name} {datetime_now}'
テーブルが定義できたらマイグレーションします。
python ./manage.py makemigrations
python ./manage.py migrate
DB更新処理の作成
models.pyがあるディレクトリにsc_manager.pyを作成し、次のように記述します。
do_scraping(sc_name)メソッドは対象のサイト名を記述すると、スクレイピングを行なってその結果を返してくれるメソッドです。内容については、requestsとBeatifulSoupを行なっているだけなので割愛します。
apschedulerのBackgroundSchedulerを使用すると、指定した処理を定期的に実行してくれるようになります。
apschedulerのインストールについては、次の手順で行います。
# sc_manager.py
import datetime
from .models import ScrapingData
from apscheduler.schedulers.background import BackgroundScheduler
# スクレイピングデータをDBに保存するメソッド
def ScrapingDataUpdateDB(sc_name):
# DBにスクレイピング対象のデータ保存用レコードがない場合、
# スクレイピング処理を行い、レコードを追加する。(insert)
if not ScrapingData.objects.filter(name=sc_name):
db = ScrapingData(name=sc_name, scraping_data=do_scraping(sc_name))
db.save()
# DBからスクレイピングデータを取得
query_set_obj = ScrapingData.objects.all().filter(name=sc_name)
pk = query_set_obj[0].pk
# スクレイピング処理を行い、DBを更新する。(update)
datetime_now = datetime.datetime.now()
scraping_result = do_scraping(sc_name)
db = ScrapingData(pk=pk, name=sc_name, scraping_data=scraping_result, update_at=datetime_now)
db.save()
# 一括でスクレイピングデータをDBに保存するメソッド
def do_db_update():
# スクレイピングの実行とDBへの登録
ScrapingDataUpdateDB("NikkeiTrendyRank") # No.1
ScrapingDataUpdateDB("AudioBookWeekRank") # No.2
ScrapingDataUpdateDB("TechcrunchPopularPost") # No.3
ScrapingDataUpdateDB("MinkabuRankingPost") # No.4
ScrapingDataUpdateDB("CodeZinePopularPost") # No.5
ScrapingDataUpdateDB("NikkeiBusinessPost") # No.6
ScrapingDataUpdateDB("PresidentPost") # No.7
ScrapingDataUpdateDB("CnetPost") # No.8
ScrapingDataUpdateDB("TokyoIpoPost") # No.9
def start():
scheduler = BackgroundScheduler()
# 1時間ごとにスクレイピングをおこなう seconds,daysも使用可能。
scheduler.add_job(do_db_update, 'interval', minutes=60)
scheduler.start()
「scheduler.add_job」の第一引数に定期実行したい処理を記述しておきます。
第二引数には、定期実行させる時間の間隔を指定します。
「minutes=60」とすると1時間おきに指定した処理を実行するようになります。
minutesの他にも、secondsやdaysも指定可能です。
apschedulerのインストール
指定した処理を一定間隔で実行するライブラリをインストールします。
pip install apscheduler
apschedulerを利用する準備
models.pyがあるディレクトリのapp.pyを次のように設定します。
'アプリ名'の箇所は自分で設定したDjangoアプリの名前を設定します。
from django.apps import AppConfig
class アプリ名Config(AppConfig):
name = 'アプリ名'
def ready(self):
# sc_manager.py作った start関数をインポート
from .sc_manager import start
start()
settings.pyにapp.pyで設定したConfigを記載します。
INSTALLED_APPS = [
...
# 追加
'アプリ名.apps.JpFundamentalApiConfig',
...
]
これで、「python manage.py runserver」を行えば、「sc_manager.py」の「do_db_update()」が1時間ごとに実行されるようになります。
あとは、views.pyでこのデータをDBから取得し、テンプレートに表示させるだけです。
from django.shortcuts import get_object_or_404,redirect,render
from .models import ScrapingData
def WebScrapingView(request):
sc_name_list = [ '対象のサイト名1', '対象のサイト名2', ・・・]
sc_result_list = []
for sc_name in sc_name_list
query_set_obj = ScrapingData.objects.all().filter(name=sc_name)
sc_result_list = query_set_obj[0].scraping_data
# テンプレートへ送信するデータを準備する
context = {'対象のサイト名1': sc_result_list[0], '対象のサイト名2': sc_result_list[1], ・・・}
return render(request, 'app_name/scraping.html', context)
この状態でページを表示させると次のような結果となります。
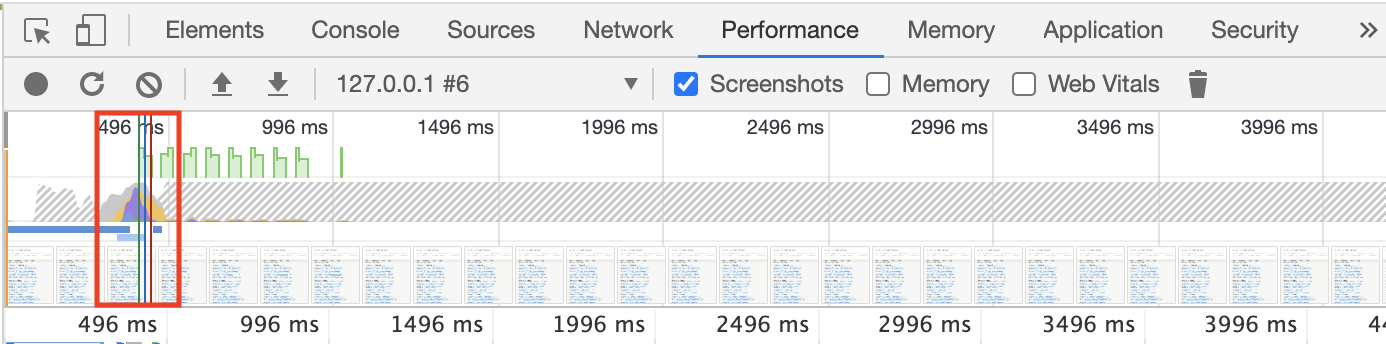
表示速度はだいたい0.5秒くらいですね。
改修前より約10倍速くなりました。
実物がこちらです。Trend Checker
以上で高速化完了です。
APScheduler利用方法については、こちらのサイトを参考にさせて頂きました。
https://note.com/masato1230/n/nd99f77e75747