terraformを使用してdynamoDBのカラムに文字列リストをfor_eachで登録しようとした際、CSVファイルで「,」や「"」が上手く利用できず苦労したのでメモ書きします。(リソース:aws_dynamodb_table_item)
カラムはidとip_listで、idは文字列、ip_listは文字列のリストとして登録します。
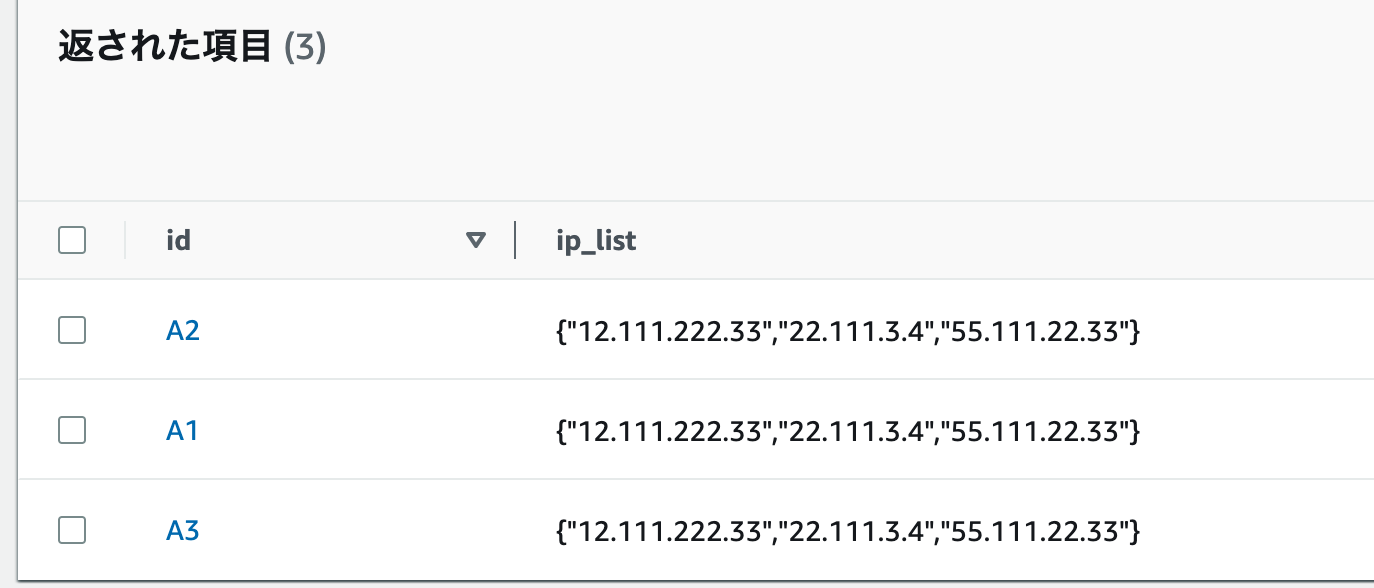
下記のdynamodb.tfとtest.csvファイルは同じディレクトリにあるものとします。
・DynamoDBで使用できるデータ型
amazondynamodb/DynamoDBMapper.DataTypes.html
# dynamodb.tf
locals {
csv_data = file("test.csv")
items_dataset = csvdecode(local.csv_data)
}
resource "aws_dynamodb_table" "this" {
name = "test_table"
tags = "test"
billing_mode = "PAY_PER_REQUEST"
hash_key = "id"
range_key = ""
point_in_time_recovery {
enabled = true
}
dynamic "attribute" {
for_each = var.attributes
content {
name = "id"
type = "S"
}
}
}
resource "aws_dynamodb_table_item" "this" {
for_each = { for record in local.items_dataset : record.id => record }
table_name = aws_dynamodb_table.this.name
hash_key = aws_dynamodb_table.this.hash_key
item = <<ITEM
{
"id": {"S": "${each.value.id}"},
"ip_list": {"SS": ["${each.value.ip_list}"]}
},
ITEM
}
CSVファイルの中でカンマを文字列として扱いたい場合は、ダブルクォーテーションで括ります。","
また、ダブルクォーテーションを文字列として扱いたい場合はダブルクォーテーションを2つ入力します。""
つまりtest.csvは下記のように記載します。
# test.csv
id,ip_list
A1,"12.111.222.33"",""22.111.3.4"",""55.111.22.33"
A2,"12.111.222.33"",""22.111.3.4"",""55.111.22.33"
A3,"12.111.222.33"",""22.111.3.4"",""55.111.22.33"
カンマのダブルクォーテーションは最初と最後のダブルクォーテーションで文字列として認識させています。
例を出すと"IP1, IP2, IP3"のような書き方をするとカンマは文字列として扱われます。