この記事ではPythonを使ってYahoo!ニュースの主要見出しとURLの情報を取得する方法を紹介します。
動画で勉強したい方はこちら。(本記事はこちらの動画を参考に作成しています)
Pythonによるビジネスに役立つWebスクレイピング(BeautifulSoup、Selenium、Requests)
また、後半では記事見出しのURLから記事本文を取得する方法も記載しています。
Webスクレイピングとは
Webスクレイピングとは"Web上から特定のデータを取得し、利用しやすく加工すること"です。
Pythonなどのプログラミング言語を使用し、プログラムを作成することで、自分の取得したいWeb上の情報を自動で取得・加工できるようになります。
ライブラリのインストール
PythonでWebスクレイピングをするにはrequestsとBeautifulSoupを事前にインストールしておく必要があります。
Macならターミナル、Windowsならコマンドプロンプトを使用して、以下のコマンドを実行するとインストールできます。
pip install requests
pip install beautifulsoup4
【見出しとURLを取得する】ソースコードの概要
記事の取得にはrequestsとBeautifulSoupというライブラリを使用しますが、
入門編ということでコードについてはとてもシンプルです。
(上記ライブラリのインストール方法については後述)
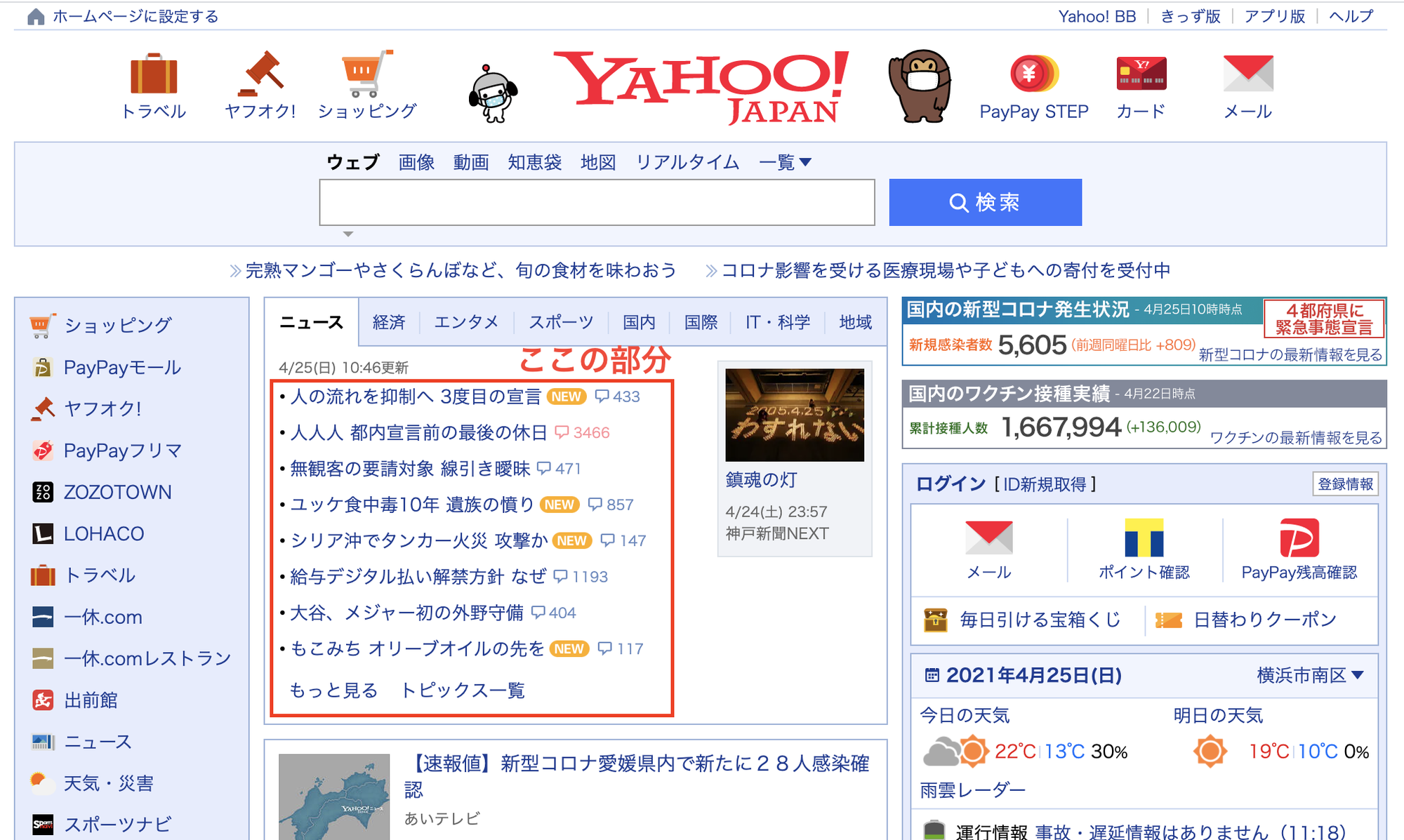
Yahoo!ニュースの主要見出しとURLの情報を取得するには、次のように記述します。
import requests
from bs4 import BeautifulSoup
import re
# ヤフーニュースのトップページ情報を取得する
URL = "https://www.yahoo.co.jp/"
rest = requests.get(URL)
# BeautifulSoupにヤフーニュースのページ内容を読み込ませる
soup = BeautifulSoup(rest.text, "html.parser")
# ヤフーニュースの見出しとURLの情報を取得して出力する
data_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
for data in data_list:
print(data.span.string)
print(data.attrs["href"])
このソースを実行すると次のような情報が取得できます。
# 実行結果(2021/05/03)
東京 新たに708人の感染確認
https://news.yahoo.co.jp/pickup/6392333
届かぬワクチン打て 自治体混乱
https://news.yahoo.co.jp/pickup/6392328
西村氏 お札触ったら手洗いを
https://news.yahoo.co.jp/pickup/6392335
減らない電柱 初の実態調査へ
https://news.yahoo.co.jp/pickup/6392336
「完全復活」たいめいけん3代目
https://news.yahoo.co.jp/pickup/6392332
Pontaポイントの障害が解消
https://news.yahoo.co.jp/pickup/6392334
大塚千弘、第1子出産を報告
https://news.yahoo.co.jp/pickup/6392331
仕事激増? イメチェンの芸能人
https://news.yahoo.co.jp/pickup/6392326
【見出しとURLを取得する】ソースコードの解説
1. requests
まず requests を使用して、Yahoo!ニューストップページの全ての情報を取得します。
URL = "https://www.yahoo.co.jp/"
rest = requests.get(URL)
requestsとは、PythonでWebページの情報を取得するためのモジュールのことです。
(Webページの情報取得には urllib.request も使用できます)
requests.get(URL)と書くと、URLで指定したページを取得することができます。
上記プログラムでは、その結果を変数 rest で受け取っています。
2. BeautifulSoup
次にBeautifulSoupで取得した記事情報を解析します。
soup = BeautifulSoup(rest.text, "html.parser")
BeautifulSoupとは、HTML や XML からデータを抽出するためのライブラリのことです。
BeautifulSoup( htmlデータ , "html.parser") と記述することで、
htmlデータ(rest.text)をプログラムで扱えるようなデータ構造に変換することができます。参考1 : Beautiful Soup 4.2.0 Doc. パーサーの指定
第一引数でhtmlのデータを渡しています。
htmlのデータは、requestsで取得したURL情報に対して、「.text」を付けることで取得できます。 余談ですが、print(rest.text)でhtmlデータの中身を確認することができます 参考2 : requests-docs-ja.readthedocs
第二引数で"html.parser"を指定しています。
これは、BeautifulSoupで htmlデータを解析するために必要な引数となります。
3. データの抽出
soup = BeautifulSoup(rest.text, "html.parser")
soup.find_all() でhtmlデータ内の href属性に「news.yahoo.co.jp/pickup」が含まれる行を抽出してdata_list に格納しています。参考 3 : Beautiful Soup 4.2.0 Doc. find-all
なぜこの行を抽出するかというと、 href属性に「news.yahoo.co.jp/pickup」が含まれるリンクがヤフーニュース見出しのURLとなっているからです。
その情報を確認するためには、Google Chromeを使用します。[ インストール ]
まず、Google Chromeでyahoo!ニュースにアクセスします。
アクセスしたら、今回スクレイピングをするヤフーニュースの見出し部分にカーソルを合わせた状態で右クリック→検証の順にクリックします。
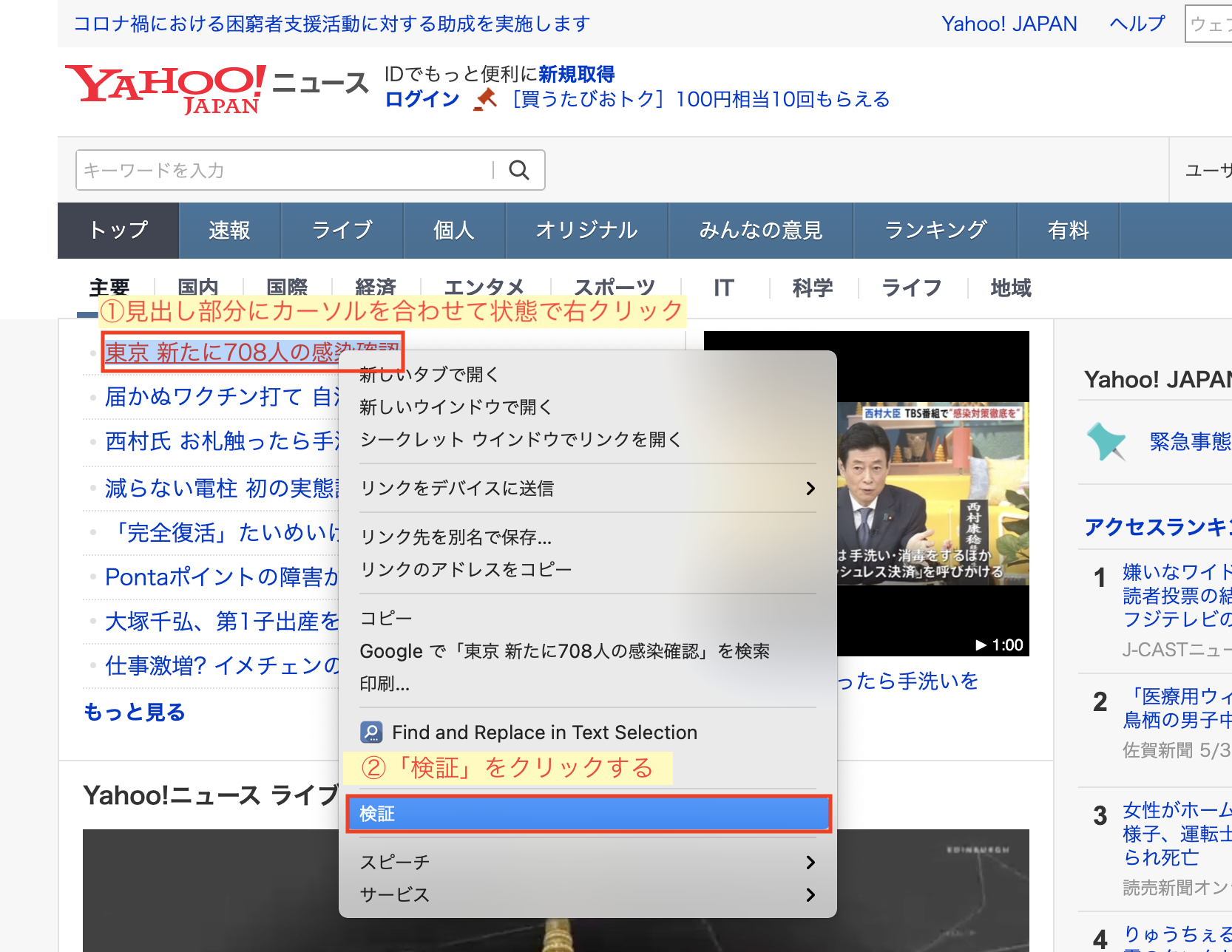
検証をクリックすると、ページの右側に次のようなウインドウが表示されます。
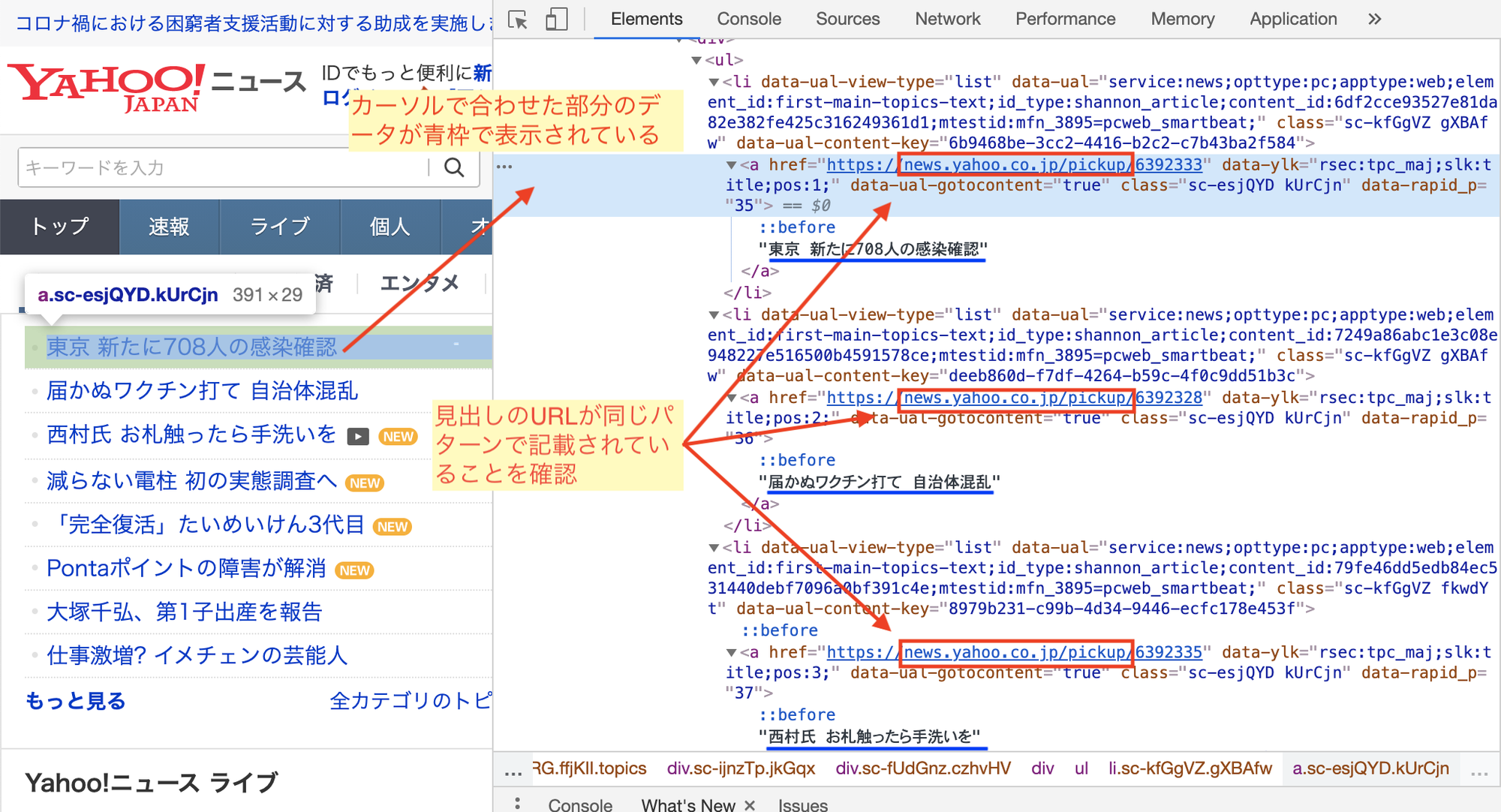
これはGoogle Chromeのデベロッパーツールというもので、Webページの解析を行うことができます。
カーソルを合わせた箇所で「検証」をクリックすることで、カーソル箇所のhtmlの記述を表示してくれます。
ここで、href属性に着目すると、見出しの href属性には全て「news.yahoo.co.jp/pickup」が含まれていることが確認できます。
次の処理でサイトに存在する 「href属性かつnews.yahoo.co.jp/pickupが含まれる箇所」を全て抽出します。
data_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
結果、data_listには次のような抽出結果が格納されます。
data_listはリスト型になっており、news.yahoo.co.jp/pickupの単位でデータ格納されます。
下の例でいえば カンマ( , )単位です。
[<a class="yMWCYupQNdgppL-NV6sMi _3sAlKGsIBCxTUbNi86oSjt"
data-ual-gotocontent="true" data-ylk="rsec:tpto;slk:title;pos:1;tpid:6392337;imgsize:s;cmt_num:0" href="https://news.yahoo.co.jp/pickup/6392337">
<div class="_2cXD1uC4eaOih4-zkRgqjU">
<div class="TRuzXRRZHRqbqgLUCCco9">
<h1 class="_3cl937Zpn1ce8mDKd5kp7u">
<span class="fQMqQTGJTbIMxjQwZA2zk _3tGRl6x9iIWRiFTkKl3kcR">
東京 新たに708人の感染確認
</span>
</h1><span class="_2obRU_TgAxzHaYqOXrZYlv">
<span class="h4yLXygiSc5wwNlJOQEdz _1dr5aVDbNPF63JCS2bJhij _2M3AyDfFaeJl3Uo7lUPMAp" style="width:30px;height:12px">
NEW</span></span></div>
</div>
</a>,
<a class="yMWCYupQNdgppL-NV6sMi _3sAlKGsIBCxTUbNi86oSjt"
data-ual-gotocontent="true" data-ylk="rsec:tpto;slk:title;pos:2;tpid:6392342;imgsize:s;cmt_num:0" href="https://news.yahoo.co.jp/pickup/6392342">
<div class="_2cXD1uC4eaOih4-zkRgqjU">
<div class="TRuzXRRZHRqbqgLUCCco9">
<h1 class="_3cl937Zpn1ce8mDKd5kp7u">
<span class="fQMqQTGJTbIMxjQwZA2zk _3tGRl6x9iIWRiFTkKl3kcR">
届かぬワクチン打て 自治体混乱
</span>
</h1><span class="_2obRU_TgAxzHaYqOXrZYlv">
<span class="h4yLXygiSc5wwNlJOQEdz _1dr5aVDbNPF63JCS2bJhij _2M3AyDfFaeJl3Uo7lUPMAp" style="width:30px;height:12px">
NEW</span></span></div>
</div>
</a>,
<a class="yMWCYupQNdgppL-NV6sMi _3sAlKGsIBCxTUbNi86oSjt"
data-ual-gotocontent="true" data-ylk="rsec:tpto;slk:title;pos:3;tpid:6392335;imgsize:s;cmt_num:4060" href="https://news.yahoo.co.jp/pickup/6392335">
<div class="_2cXD1uC4eaOih4-zkRgqjU">
<div class="TRuzXRRZHRqbqgLUCCco9">
<h1 class="_3cl937Zpn1ce8mDKd5kp7u">
<span class="fQMqQTGJTbIMxjQwZA2zk _3tGRl6x9iIWRiFTkKl3kcR">
西村氏 お札触ったら手洗いを
</span>
</h1></div>
</div>
</a>,
# 以下略
]
最後に、上記リストをfor文で処理します。
data_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
for data in data_list:
print(data.span.string)
print(data.attrs["href"])
data_listをfor文で実行することで、各要素を順番に処理しています。
for文の最初の処理では、data.span.stringで spanタグに含まれる文字列を取得しています。
これで、記事の見出し部分が抽出できます。
また、string の部分は text に書き換えることも可能です。
参考4 : https://lets-hack.tech/programming/languages/python/bs4-text-or-string/)
data.attrs["属性名"]とすると、対応する属性の値を取得できます。
今回は、data.attrs["href"] とすることで、hrefに設定されている値を取得しています。
これらのコードを実行すると、最初にご紹介した通りのデータが取得できます。
# 実行結果(2021/05/03)
東京 新たに708人の感染確認
https://news.yahoo.co.jp/pickup/6392333
届かぬワクチン打て 自治体混乱
https://news.yahoo.co.jp/pickup/6392328
西村氏 お札触ったら手洗いを
https://news.yahoo.co.jp/pickup/6392335
減らない電柱 初の実態調査へ
https://news.yahoo.co.jp/pickup/6392336
「完全復活」たいめいけん3代目
https://news.yahoo.co.jp/pickup/6392332
Pontaポイントの障害が解消
https://news.yahoo.co.jp/pickup/6392334
大塚千弘、第1子出産を報告
https://news.yahoo.co.jp/pickup/6392331
仕事激増? イメチェンの芸能人
https://news.yahoo.co.jp/pickup/6392326
【応用編】記事見出しのURLから記事本文を取得、表示する方法
記事見出しのURLから記事本文を取得、表示する方法を記載します。
こちらは、先ほどの処理の応用編です。
ヤフーのページ構成は[Top] -> [要約] -> [本文] となっており、
前のコードで取得したのは、[Top] ページの見出しとそのURLです。
以下に記載しているコードは、前章で記述した[Top] の情報を取得するコードに加え、
[要約] -> [本文] を取得し、表示するコードを追記したものとなります。
コード
import requests
from bs4 import BeautifulSoup
import re
# ヤフーニュースのトップページ情報を取得する
URL = "https://www.yahoo.co.jp/"
res = requests.get(URL)
# BeautifulSoupにヤフーニュースのページ内容を読み込ませる
soup = BeautifulSoup(res.text, "html.parser")
# URLに news.yahoo.co.jp/pickup が含まれるものを抽出する。
data_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
#! ここから先を修正、追記 !#
# ヤフーニュース見出のURL情報をループで取得し、リストで格納する。
headline_link_list = [data.attrs["href"] for data in data_list]
# ヤフーニュース見出のURLリストから記事URLを取得し、記事内容を取得する
for headline_link in headline_link_list:
# ヤフーニュース見出のURLから、 要約ページの内容を取得する
summary = requests.get(headline_link)
# 取得した要約ページをBeautifulSoupで解析できるようにする
summary_soup = BeautifulSoup(summary.text, "html.parser")
# aタグの中に「続きを読む」が含まれているテキストを抽出する
# ヤフーのページ構成は[Top] -> [要約] -> [本文] となっており、
# [要約]から[本文]に遷移するには「続きを読む」をクリックする必要がある。
summary_soup_a = summary_soup.select("a:contains('続きを読む')")[0]
# aタグの中の"href="から先のテキストを抽出する。
# するとヤフーの記事本文のURLを取得できる
news_body_link = summary_soup_a.attrs["href"]
# 記事本文のURLから記事本文のページ内容を取得する
news_body = requests.get(news_body_link)
# 取得した記事本文のページをBeautifulSoupで解析できるようにする
news_soup = BeautifulSoup(news_body.text, "html.parser")
# 記事本文のタイトルを表示する
print(news_soup.title.text)
# 記事本文のURLを表示する
print(news_body_link)
# class属性の中に「Direct」が含まれる行を抽出する
detail_text = news_soup.find(class_=re.compile("Direct"))
# 記事本文を出力する
# hasattr:指定のオブジェクトが特定の属性を持っているかを確認する
# detail_text.textの内容がNoneだった場合は、何も表示しないようにしている。
print(detail_text.text if hasattr(detail_text, "text") else '', end="\n\n\n")
このコードを実行すると次のような結果となります。
結果の内容は、Topページ見出しのURLの数だけループ処理を行い、
ループ内で記事本文のページを抽出し、
抽出したページから「記事タイトル」「記事URL」「記事本文」を出力したものです。
出力結果
※表示内容が多いので、出力結果の一部を省略して記載しています。
# 実行結果(2021/04/07)
変異株の新規感染、1カ月で14倍に 子どもの割合増加(朝日新聞デジタル) - Yahoo!ニュース
https://headlines.yahoo.co.jp/hl?a=20210407-00000067-asahi-sctch
新型コロナウイルスの変異ウイルスによる新たな感染者数は1週間あたりで、2月末から3月末にかけて全国で14倍に急増した。コロナ対策を厚生労働省に助言する専門家組織は7日、関西圏を中心に変異株が感染急拡大に影響しているとして、不要不急の移動を避けるなど警戒の強化を求めた。
※ 内容省略
飲食店員「働くのが怖い」 感染者最多更新の大阪で広がる不安(毎日新聞) - Yahoo!ニュース
https://headlines.yahoo.co.jp/hl?a=20210407-00000080-mai-soci
大阪府の新規感染者が878人と初めて800人を超え、市民の間では驚きや不安が広がった。
【図で詳しく】緊急事態宣言とまん延防止措置の違い
※ 内容省略
英首相「私もパブでビールを」 感染状況が劇的改善(朝日新聞デジタル) - Yahoo!ニュース
https://headlines.yahoo.co.jp/hl?a=20210407-00000066-asahi-eurp
「私たちの努力が報われていることは明らかです」
英国のジョンソン首相は5日の会見で、1月から続く3度目のロックダウン(都市封鎖)の一部緩和に踏み出すと宣言した。
【画像】感染状況が改善している英 ロンドンの公園でピクニックを楽しむ人々
※ 内容省略
Yahoo!以外のスクレイピング
トレンドチェックツール
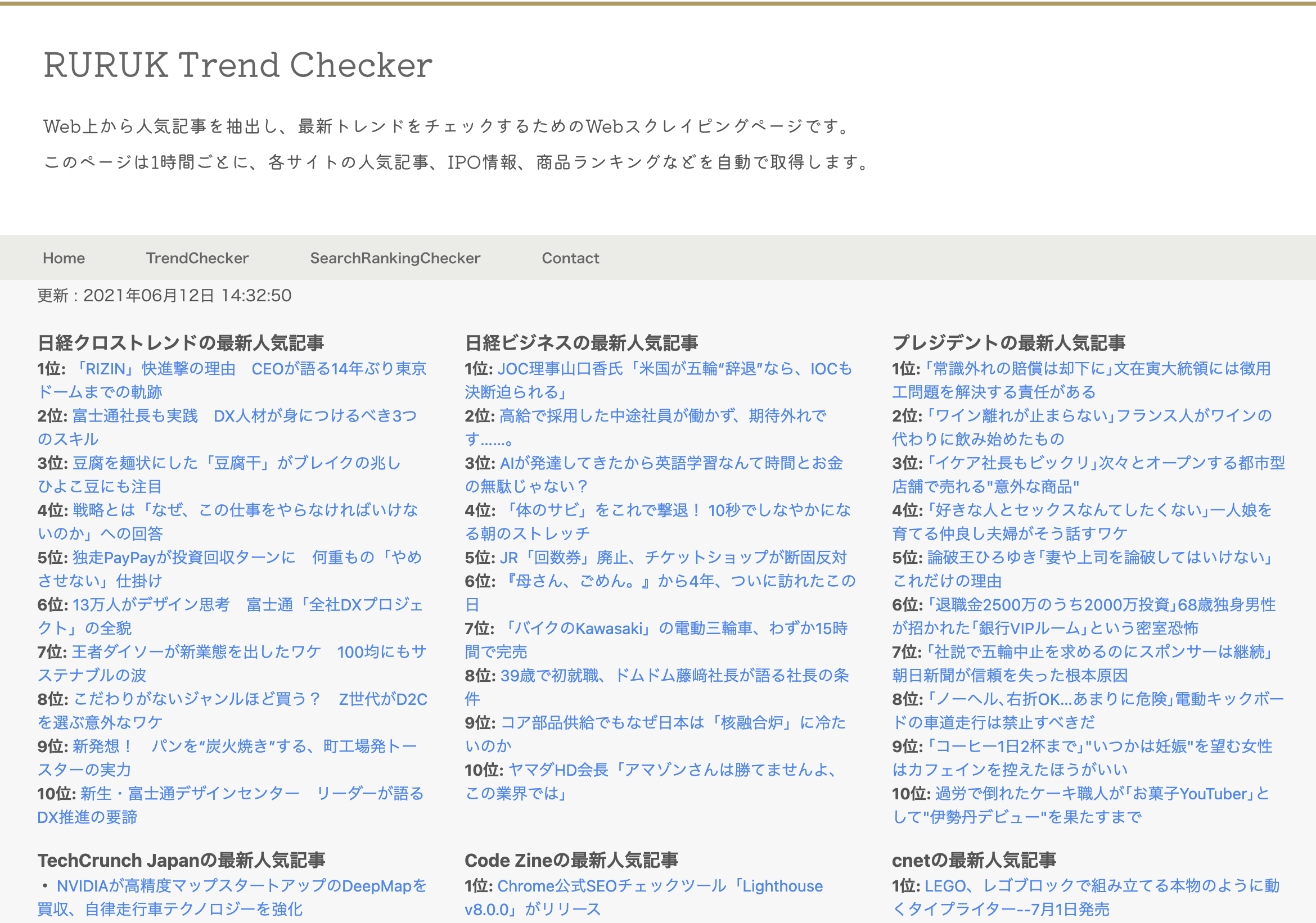
このソースを応用することで、色々なサイトから最新人気記事を抽出するツールを作成することができます。
当ブログでは次のようなツールを実装しています。
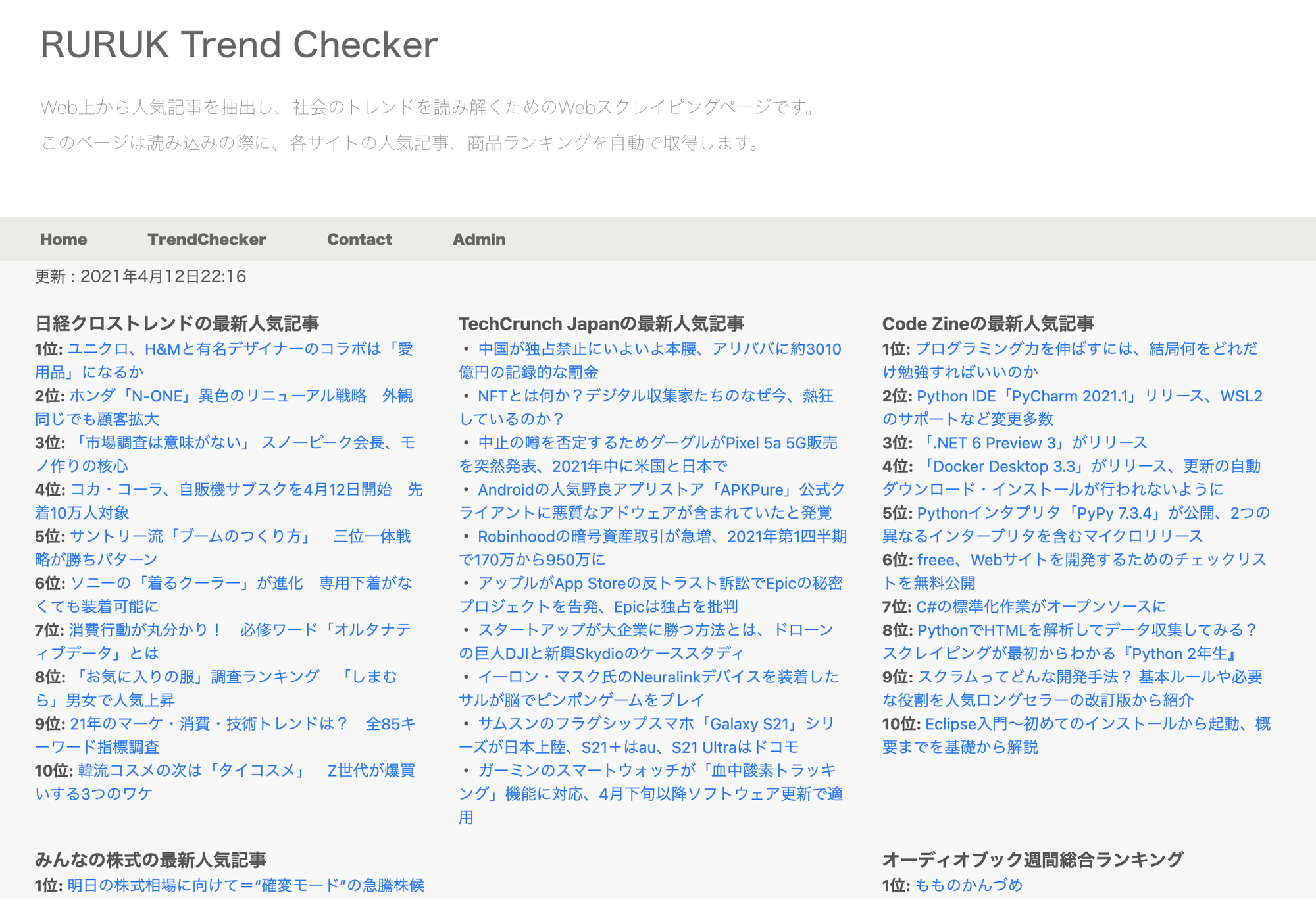
このツールでは以下のサイトの最新ランキング情報を、ページを更新するごとに取得します。
・日経クロストレンド
・TechCrunch Japan
・Code Zine
・みんなの株式
・オーディオブック(audiobook.jp)
こちらはこのツールへのリンクとなります。
今後のWebスクレイピングツール作成のご参考になれば幸いです。
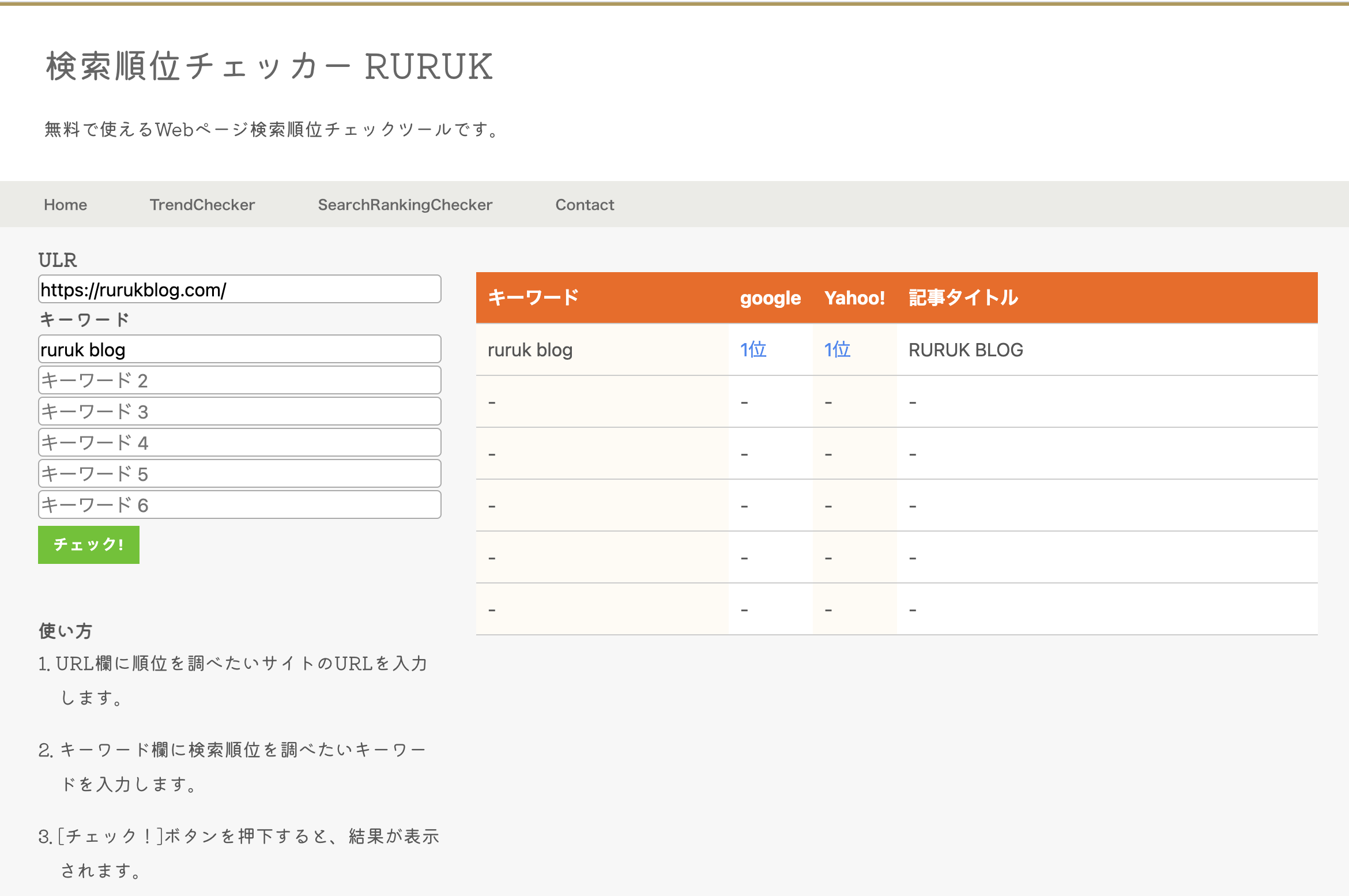
https://rurukblog.com/trend-check
検索順位チェックツール
本記事で紹介したrequestsとBeautifulSoupを利用することで、Googleの検索エンジンに対してスクレイピングを行うことができます。
そちらの方法については以下の記事にまとめています。
【Webスクレイピング入門】Google検索の上位サイトを件数指定して表示する方法
さらにこれを応用すると、ブログ内の記事の検索順位を一括で調査できるツールを作成することができます。
こちらもこのブログに実装しています。
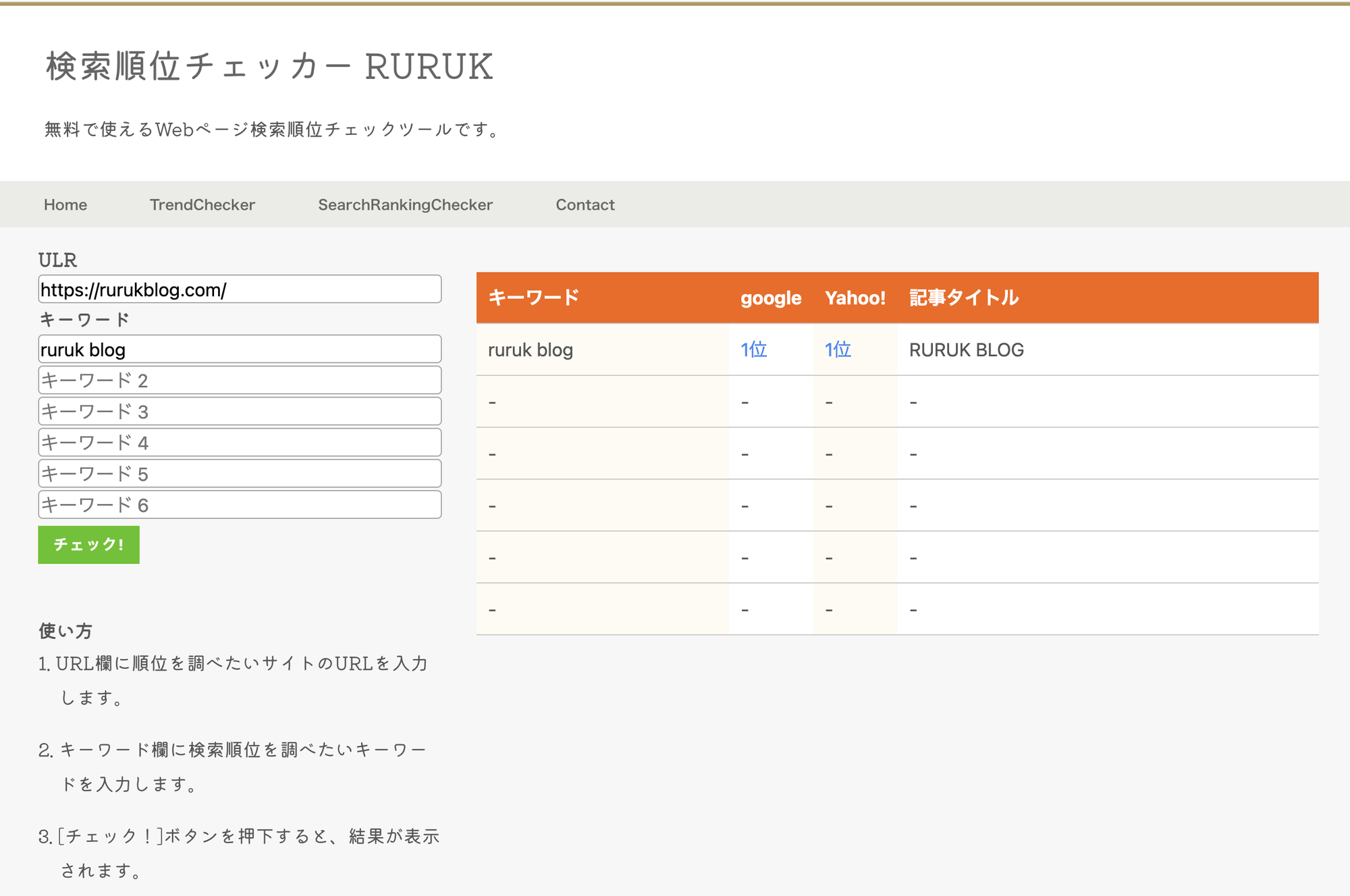
もしよければ、参考までにお試しください。

関連記事
【Webスクレイピング入門】Google検索の上位サイトを件数指定して表示する方法
【Python】Webスクレイピングの処理速度を高速化する方法
Webスクレイピングできること。社会のトレンドを観察するツールを作ってみた。
参考: Udemy
Pythonによるビジネスに役立つWebスクレイピング(BeautifulSoup、Selenium、Requests)