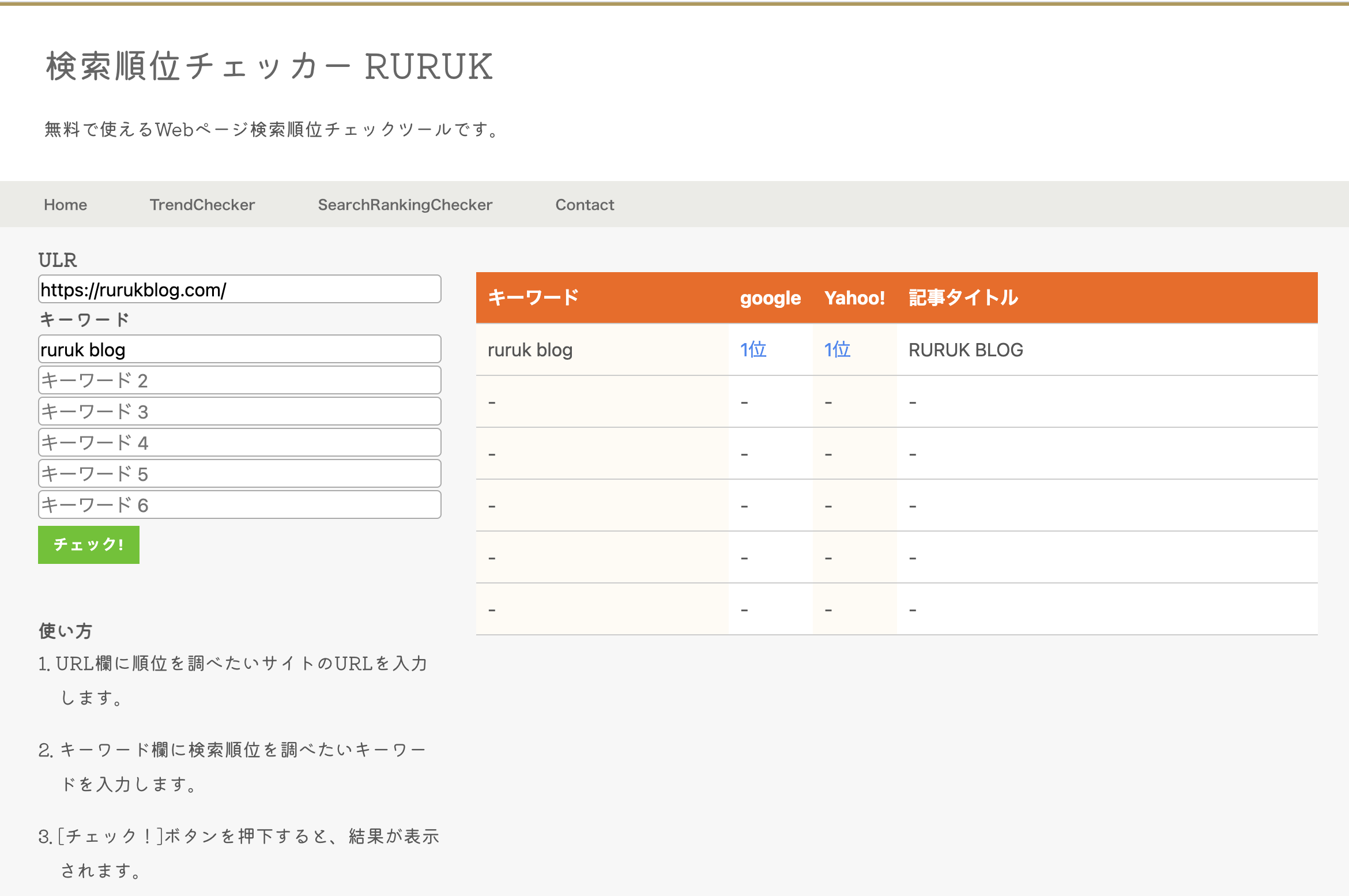
この記事では、Pythonを利用してGoogle検索の上位サイトを件数指定して表示する方法を紹介します。
比較的短いコードで実装できるため、プログラミング経験の少ない方でも、挑戦しやすい難易度となっています。
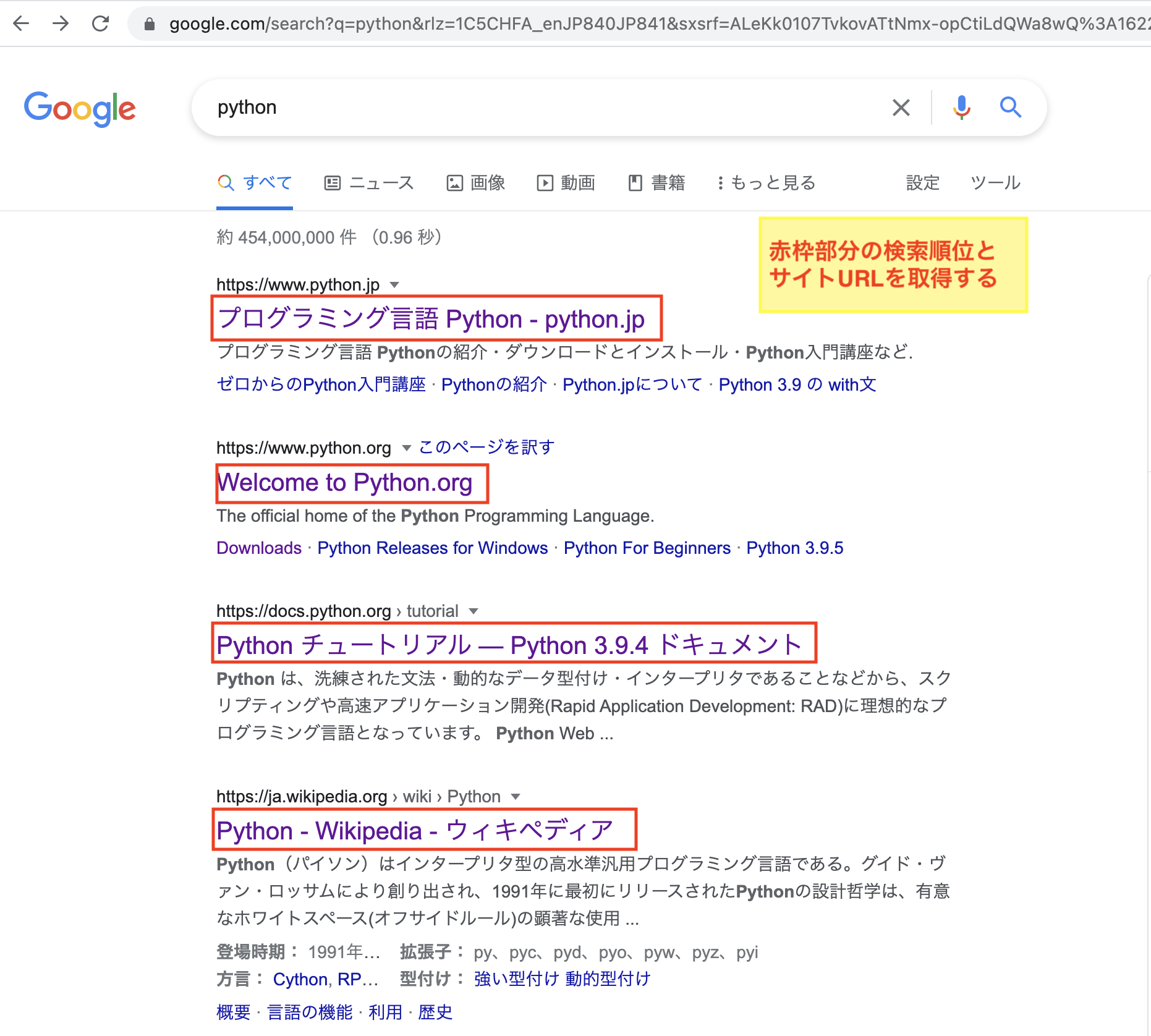
Webスクレイピングとは
Webスクレイピングとは"Web上から特定のデータを取得し、利用しやすく加工すること"です。
Pythonなどのプログラミング言語を使用し、プログラムを作成することで、自分の取得したいWeb上の情報を自動で取得・加工できるようになります。
ライブラリのインストール
PythonでWebスクレイピングをするにはrequestsとBeautifulSoupを事前にインストールしておく必要があります。
Macならターミナル、Windowsならコマンドプロンプトを使用して、以下のコマンドを実行するとインストールできます。
pip install requests
pip install beautifulsoup4
Google検索の上位サイトを件数指定して抽出するソースコード
次のようにコードを記述することで、Google検索の上位サイトを件数指定して抽出するこができます。
今回は検索キーワードにpython、表示するサイト件数を10件に設定しています。
import requests
from bs4 import BeautifulSoup
# Google検索するキーワードを設定
search_word = 'python'
# 上位から何件までのサイトを抽出するか指定する
pages_num = 10 + 1
print(f'【検索ワード】{search_word}')
# Googleから検索結果ページを取得する
url = f'https://www.google.co.jp/search?hl=ja&num={pages_num}&q={search_word}'
request = requests.get(url)
# Googleのページ解析を行う
soup = BeautifulSoup(request.text, "html.parser")
search_site_list = soup.select('div.kCrYT > a')
# ページ解析と結果の出力
for rank, site in zip(range(1, pages_num), search_site_list):
try:
site_title = site.select('h3.zBAuLc')[0].text
except IndexError:
site_title = site.select('img')[0]['alt']
site_url = site['href'].replace('/url?q=', '')
# 結果を出力する
print(str(rank) + "位: " + site_title + ": " + site_url)
【検索ワード】python
1位: python.jp: プログラミング言語 Python: https://www.python.jp/&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAAegQIBxAB&usg=AOvVaw1zWPmv7T5_TAWg3bnqmmBE
2位: Welcome to Python.org: https://www.python.org/&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjABegQICRAB&usg=AOvVaw1VKreO_0TrTsBwrZLUocgi
3位: Python チュートリアル — Python 3.9.4 ドキュメント: https://docs.python.org/ja/3/tutorial/&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjANegQICxAB&usg=AOvVaw1bDyksh3P8l05md7m4NnLw
4位: Python - Wikipedia - ウィキペディア: https://ja.wikipedia.org/wiki/Python&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAOegQIChAB&usg=AOvVaw2h6Ef4-6GaL_9mbBi6v5Of
5位: Pythonってどんな言語? 特徴と歴史を『独習Python』から解説 ...: https://codezine.jp/article/detail/12457&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjATegQIDBAB&usg=AOvVaw2CsNq7v9DmTsrwa8wpNE7k
6位: Python入門 〜Pythonのインストール方法やPythonを使った ...: https://www.javadrive.jp/python/&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAeegQIARAB&usg=AOvVaw1eO3_CVpXxxKsCtVl9vWak
7位: Pythonのダウンロードとインストール | Python入門: https://www.javadrive.jp/python/install/index1.html&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAfegQIAhAB&usg=AOvVaw18RA3hDQzun_a1PvXcBXG6
8位: Python | プログラミングの入門なら基礎から学べるProgate[プロ ...: https://prog-8.com/courses/python&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAgegQIAxAB&usg=AOvVaw0WS_ZSGAG25fV3jTtUqiyv
9位: Python3入門編のレッスン一覧 | プログラミング学習サービス ... - Paiza: https://paiza.jp/works/python3/primer&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAhegQICBAB&usg=AOvVaw20iAjA8YLRB_xDFBrPEhBH
10位: PyQ(パイキュー) - 本気でプログラミングを学びたい人のPython ...: https://pyq.jp/&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAiegQIBhAB&usg=AOvVaw0-cv27f91EEeVZL8-f50eF
ソースコードの解説
ライブラリのimport
import requests
from bs4 import BeautifulSoup
冒頭でインストールしたライブラリをプログラム上で利用できるようにしています。
抽出条件の設定
# Google検索するキーワードを設定
search_word = 'python'
# 検索上位から何件までのサイトを抽出するか指定する
pages_num = 10 + 1
print(f'【検索ワード】{search_word}')
search_wordは、Google検索を行うキーワードを設定します。
pages_numは、検索上位から何件までのサイトを抽出するか指定します。
後述するURLの仕様上、表示したい件数にプラス1しないと表示サイトが1件少なくなるため、+ 1を記述しています。
print(f'【検索ワード】{search_word}')で実行結果画面に検索に使ったキーワードを表示しています。
Googleから検索結果ページを取得する
# Googleから検索結果ページを取得する
url = f'https://www.google.co.jp/search?hl=ja&num={pages_num}&q={search_word}'
request = requests.get(url)
urlの箇所でGoogleへ接続するためのURLを設定しています。
URLのパラメータであるnum=に数字を設定すると表示する検索結果ページの数が設定できます。
また、q=に検索したいキーワードを設定するとそのキーワードの結果ページが得られます。
次の行のrequests を使用すると、urlで設定したWebページの情報を取得できます。
requests.get(url) と記述することで、どのサイトからもWebページの情報を取得できますが、今回はgoogleの検索結果ページを取得しています。
検索結果ページの解析準備をする
soup = BeautifulSoup(request.text, "html.parser")
BeautifulSoupでrequestsで取得したページを解析しています。
BeautifulSoupとは、HTML や XML からデータを抽出するためのライブラリのことです。
BeautifulSoup( htmlデータ , "html.parser") と記述することで、
htmlデータ(rest.text)をプログラムで扱えるようなデータ構造に変換することができます。参考1 : Beautiful Soup 4.2.0 Doc. パーサーの指定
第一引数でhtmlのデータを渡しています。
htmlのデータは、requestsで取得したURL情報に対して、「.text」を付けることで取得できます。
また、今回のコードには記述していませんが、print(rest.text)でhtmlデータの中身を確認することができます。参考2 : requests-docs-ja.readthedocs
これを利用して、BeautifulSoupでページのどこを抽出するべきかを確認できます。
第二引数で"html.parser"を指定しています。
これは、BeautifulSoupで htmlデータを解析するために必要な引数となります。
検索結果ページを解析する
search_site_list = soup.select('div.kCrYT > a')
Googleの検索結果ページの中で、サイトのタイトルとURLが含まれる部分を抽出しています。
具体的には、ページ内で<div class="kCrYT"><a> サイトのタイトル </a></div> となっている箇所が対象となるので、その部分をそれぞれ抽出してsearch_site_listに格納しています。
イメージとしては、サイトタイトルごとに以下のようなコードが記述されているので、それをsoup.select('div.kCrYT > a')で引き抜いて、抽出したサイトごとにsearch_site_listに格納しています。
# -- 中略 --
<div class="kCrYT">
<a href="/url?q=https://www.python.jp/&sa=U&ved=2ahUKEwj84KDd3f_wAhUQWqwKHWSJDQUQFjAAegQIBxAB&usg=AOvVaw0-xlf0dVVFo6iwHbFnLFue"><h3 class="zBAuLc">
<div class="BNeawe vvjwJb AP7Wnd">python.jp: プログラミング言語 Python
</div>
</h3>
<div class="BNeawe UPmit AP7Wnd">www.python.jp</div>
</a>
</div>
<div class="x54gtf">
</div>
# -- 以下このパターンの記述が続く --
ページ解析の続きと結果の出力
# ページ解析と結果の出力
for rank, site in zip(range(1, pages_num), search_site_list):
try:
site_title = site.select('h3.zBAuLc')[0].text
except IndexError:
site_title = site.select('img')[0]['alt']
site_url = site['href'].replace('/url?q=', '')
# 結果を出力する
print(str(rank) + "位: " + site_title + ": " + site_url)
先ほどsearch_site_listで取得したデータを元に、ページ解析と結果の出力を行なっています。
サイトごとにループ処理を実行
for rank, site in zip(range(1, pages_num), search_site_list):
for文でサイトごとにデータを取り出し、解析と結果出力をおこなっています。
rankには1から順番に数字が入ります。つまりfor文が2回目なら2が入ります。
ここを利用して検索順位を表示させます。
site部分には、search_site_listから取り出したデータがforの処理の順番に入ります。
zipを使用することで、forループで複数のリストを利用できるようになります。
また、rangeを使用することで、数字のリストを簡単に作成することができます。
サイトタイトルの取得
try:
site_title = site.select('h3.zBAuLc')[0].text
except IndexError:
site_title = site.select('img')[0]['alt']
再び、BeautifulSoupのselectでデータ抽出を行なっています。
こちらはサイトタイトルを取得する処理です。
最初のsite.select('h3.zBAuLc')[0]では、<h3 class="zBAuLc"/>サイトタイトル/</h3>部分を抽出しています。
イメージとしては、以下のようになります。
<h3 class="zBAuLc">
<div class="BNeawe vvjwJb AP7Wnd">python.jp: プログラミング言語 Python
</div>
</h3>
site.select('h3.zBAuLc')[0]のコードのうしろに.textという記述がありますが、これはタグ内のテキスト部分を抜き出す処理となります。
site.select('h3.zBAuLc')[0].textと記述すると、上記のデータは次のようになります。
python.jp: プログラミング言語 Python
これでタイトル部分の抜き出しは完了です。
基本的に処理はこれで終了しますが、サイトのタイトル部分が動画タイトルになっていると、この処理はエラーとなります。
動画タイトルであった場合は、except IndexError:処理の次のコードが実行され、動画タイトルを取得します。
サイトURLの取得
site_url = site['href'].replace('/url?q=', '')
site['href']と指定するとaタグ内のhref属性に含まれるデータを抽出できます。
この処理の実行例は次の通りです。
/url?q=https://www.python.jp/&sa=U&ved=2ahUKEwj84KDd3f_wAhUQWqwKHWSJDQUQFjAAegQIBxAB&usg=AOvVaw0-xlf0dVVFo6iwHbFnLFue
これでURLが抽出できましたが、url?q=部分が邪魔です。
なのでreplaceを利用してurl?q=を削除します。
そうするとデータは次のようになります。
https://www.python.jp/&sa=U&ved=2ahUKEwj84KDd3f_wAhUQWqwKHWSJDQUQFjAAegQIBxAB&usg=AOvVaw0-xlf0dVVFo6iwHbFnLFue
結果を出力する
# 結果を出力する
print(str(rank) + "位: " + site_title + ": " + site_url)
最後に抽出したデータを画面に出力します。
rankは数値型なので、文字列と結合できません。
そのため、str(rank)とすることでrankを文字列型に変換しています。
この出力結果をfor文の回数だけ実行すると、冒頭で紹介した実行結果となります。
【検索ワード】python
1位: python.jp: プログラミング言語 Python: https://www.python.jp/&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAAegQIBxAB&usg=AOvVaw1zWPmv7T5_TAWg3bnqmmBE
2位: Welcome to Python.org: https://www.python.org/&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjABegQICRAB&usg=AOvVaw1VKreO_0TrTsBwrZLUocgi
3位: Python チュートリアル — Python 3.9.4 ドキュメント: https://docs.python.org/ja/3/tutorial/&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjANegQICxAB&usg=AOvVaw1bDyksh3P8l05md7m4NnLw
4位: Python - Wikipedia - ウィキペディア: https://ja.wikipedia.org/wiki/Python&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAOegQIChAB&usg=AOvVaw2h6Ef4-6GaL_9mbBi6v5Of
5位: Pythonってどんな言語? 特徴と歴史を『独習Python』から解説 ...: https://codezine.jp/article/detail/12457&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjATegQIDBAB&usg=AOvVaw2CsNq7v9DmTsrwa8wpNE7k
6位: Python入門 〜Pythonのインストール方法やPythonを使った ...: https://www.javadrive.jp/python/&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAeegQIARAB&usg=AOvVaw1eO3_CVpXxxKsCtVl9vWak
7位: Pythonのダウンロードとインストール | Python入門: https://www.javadrive.jp/python/install/index1.html&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAfegQIAhAB&usg=AOvVaw18RA3hDQzun_a1PvXcBXG6
8位: Python | プログラミングの入門なら基礎から学べるProgate[プロ ...: https://prog-8.com/courses/python&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAgegQIAxAB&usg=AOvVaw0WS_ZSGAG25fV3jTtUqiyv
9位: Python3入門編のレッスン一覧 | プログラミング学習サービス ... - Paiza: https://paiza.jp/works/python3/primer&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAhegQICBAB&usg=AOvVaw20iAjA8YLRB_xDFBrPEhBH
10位: PyQ(パイキュー) - 本気でプログラミングを学びたい人のPython ...: https://pyq.jp/&sa=U&ved=2ahUKEwi0jeHE8f_wAhX6HDQIHep7ATYQFjAiegQIBhAB&usg=AOvVaw0-cv27f91EEeVZL8-f50eF
応用編
本記事の内容を応用することで、ブログ内の記事の検索順位を一括で調査できるツールを作成することができます。
こちらはこのブログに実装されています。
もしよければ、参考までにお試しください。
関連記事
【Webスクレイピング入門】ヤフーニュース の見出しとURLを取得する方法
【Python】Webスクレイピングの処理速度を高速化する方法
・Webスクレイピングできること。社会のトレンドを観察するツールを作ってみた。