PythonでWebスクレイピングの勉強をした、またはこれから勉強するけど、
Webスクレイピングって具体的に何ができるの?
このような疑問をお持ちの方の参考になればと思い、この記事を書きました。
私も同じように、Webスクレイピングを勉強したものの、「これでいったい何ができるんじゃ!」状態だったので、今回は、大手のWebサイトから人気記事を抽出することで、社会のトレンドを観察するツールを作ってみました。
そもそもWebスクレイピングって何?
Webサイトから情報を抽出するコンピュータソフトウェア技術のことです。
たとえば、Webスクレイピングを利用することで、ニュースや株価などといった自分好みの情報を効率良く取得することができます。
Pythonではrequests、beautifulsoup、seleniumなどのライブラリを使用することで、容易に実装が行えます。
Webスクレイピングツールの例
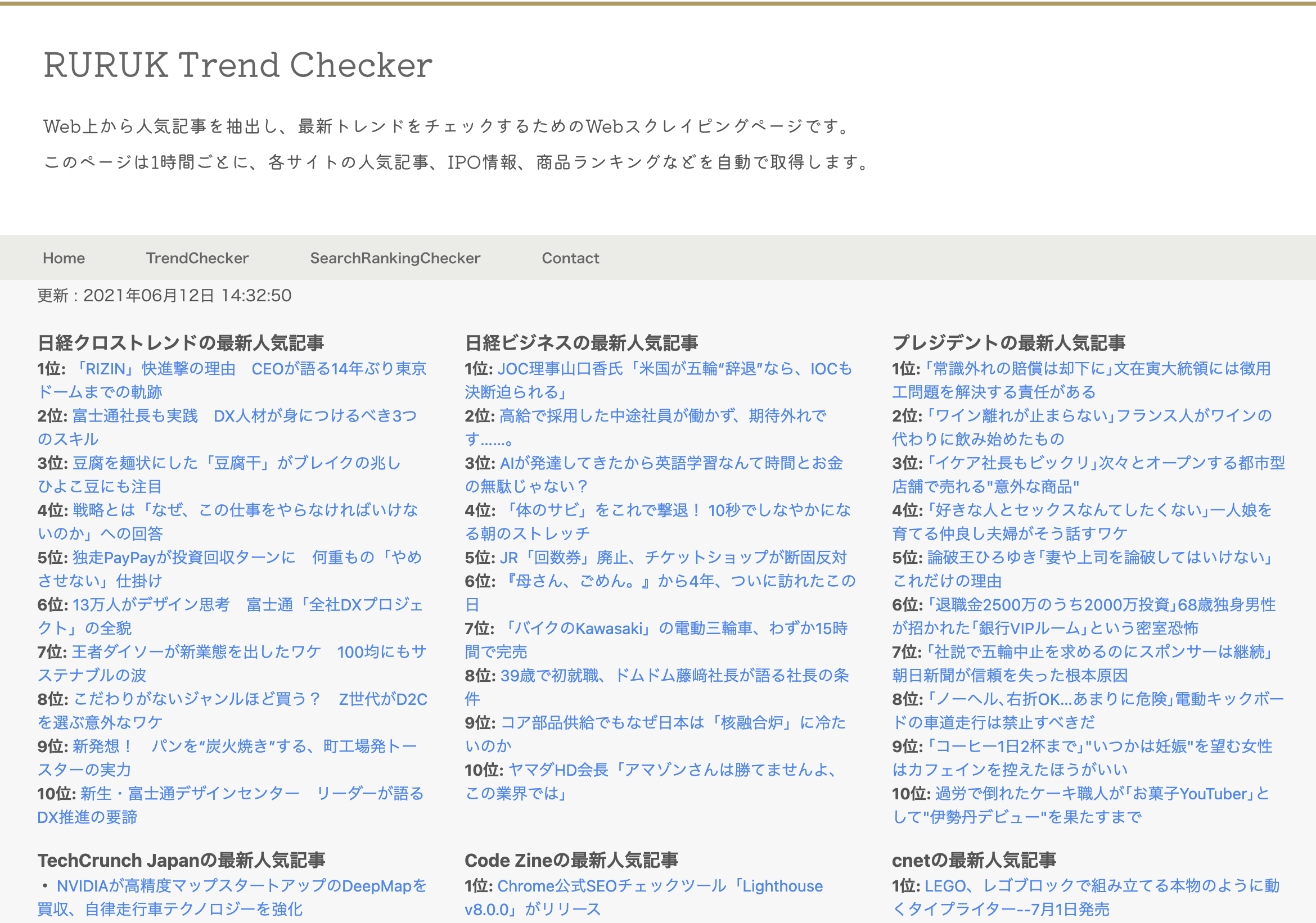
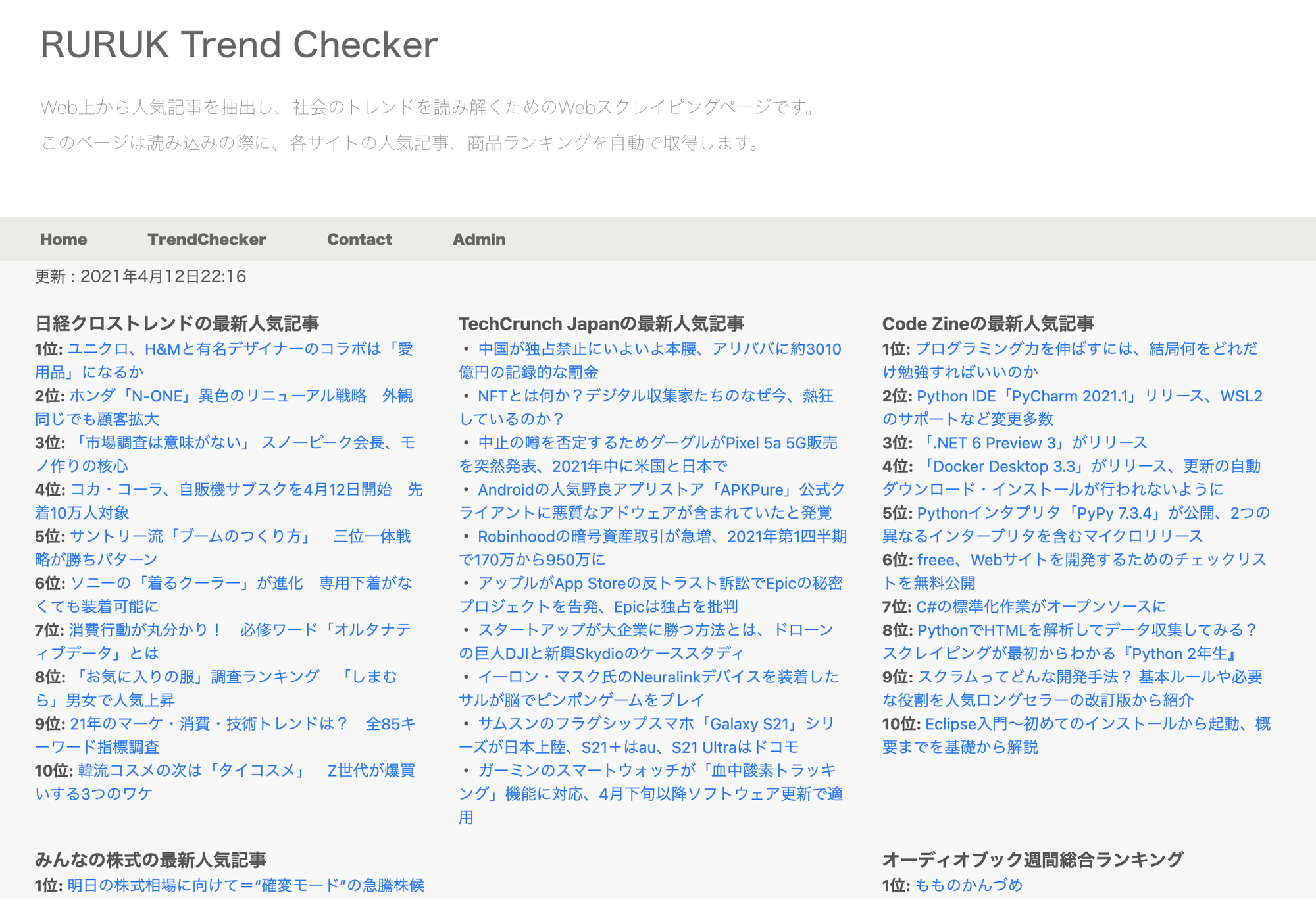
冒頭でもお話しましたが、今回は大手のWebサイトから人気記事を抽出することで、社会のトレンドを観察するツールを作ってみました。
ただ、いちいち開発環境(PycharmやVisual Studio Code等)から実行するのは不便なので、GUIベースで作成を行っています。
こちらが作成したツールのイメージ画像です。
ここでGUIという単語が出てきましたが、WebスクレイピングツールはDjangoやFlaskなどを使用してWebブラウザに結果を表示することができます。
GUIにすることで、視認性の向上もさることながら、スクレイピンの実行がWebブラウザのリロードだけで済むというメリットがあります。
ただ、抽出データをDBに定期保存したい場合は、Linuxなどによる定期ジョブ実行を設定した方が良いと思います。
GoogleからWebスクレイピングするツール(2021/06/19 更新)
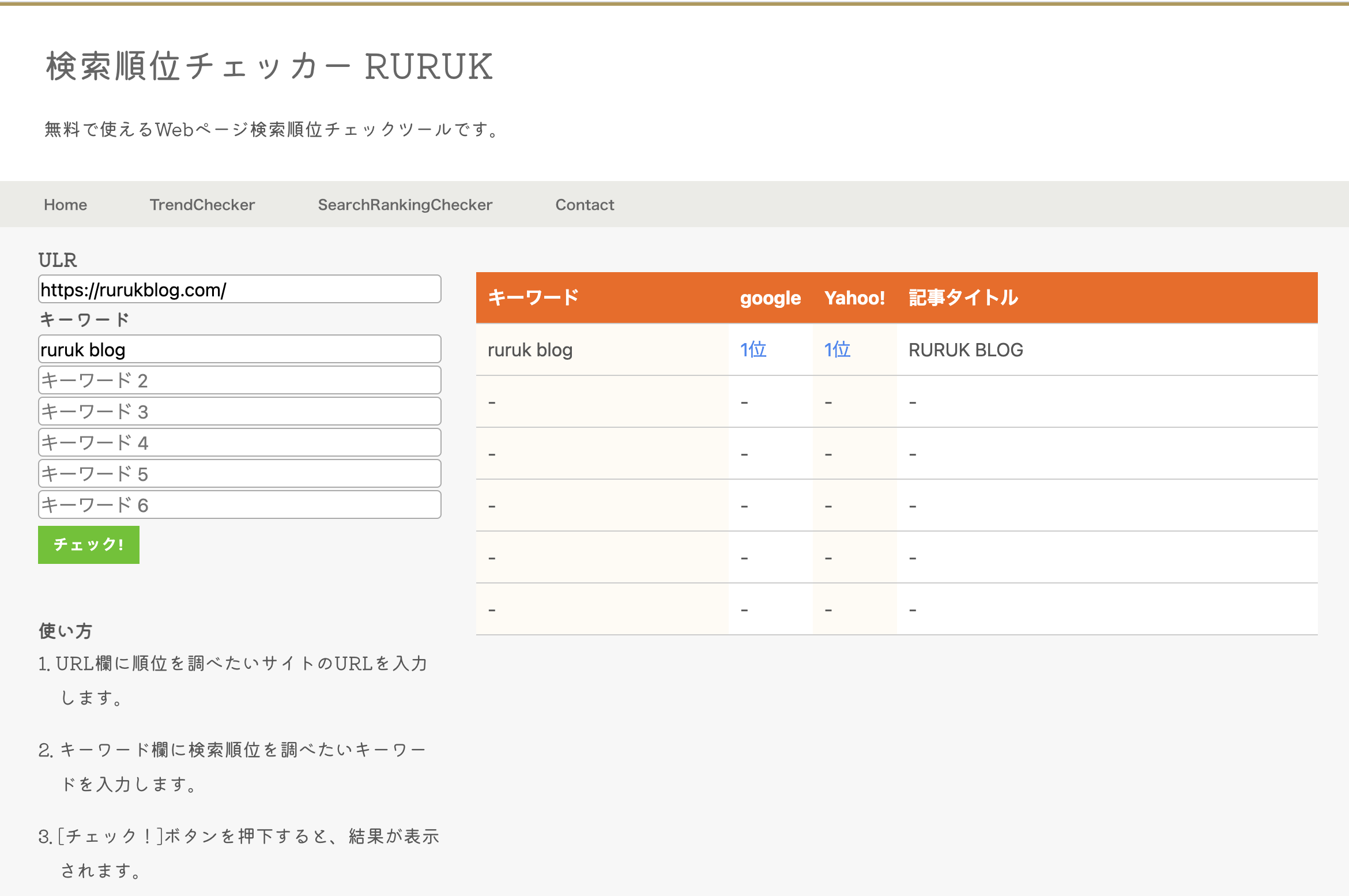
Googleの検索エンジンをスクレイピングすることで、ブログやWebサイト内にある記事の検索順位を一括調査できるツールを作成しました。
検索順位チェッカー
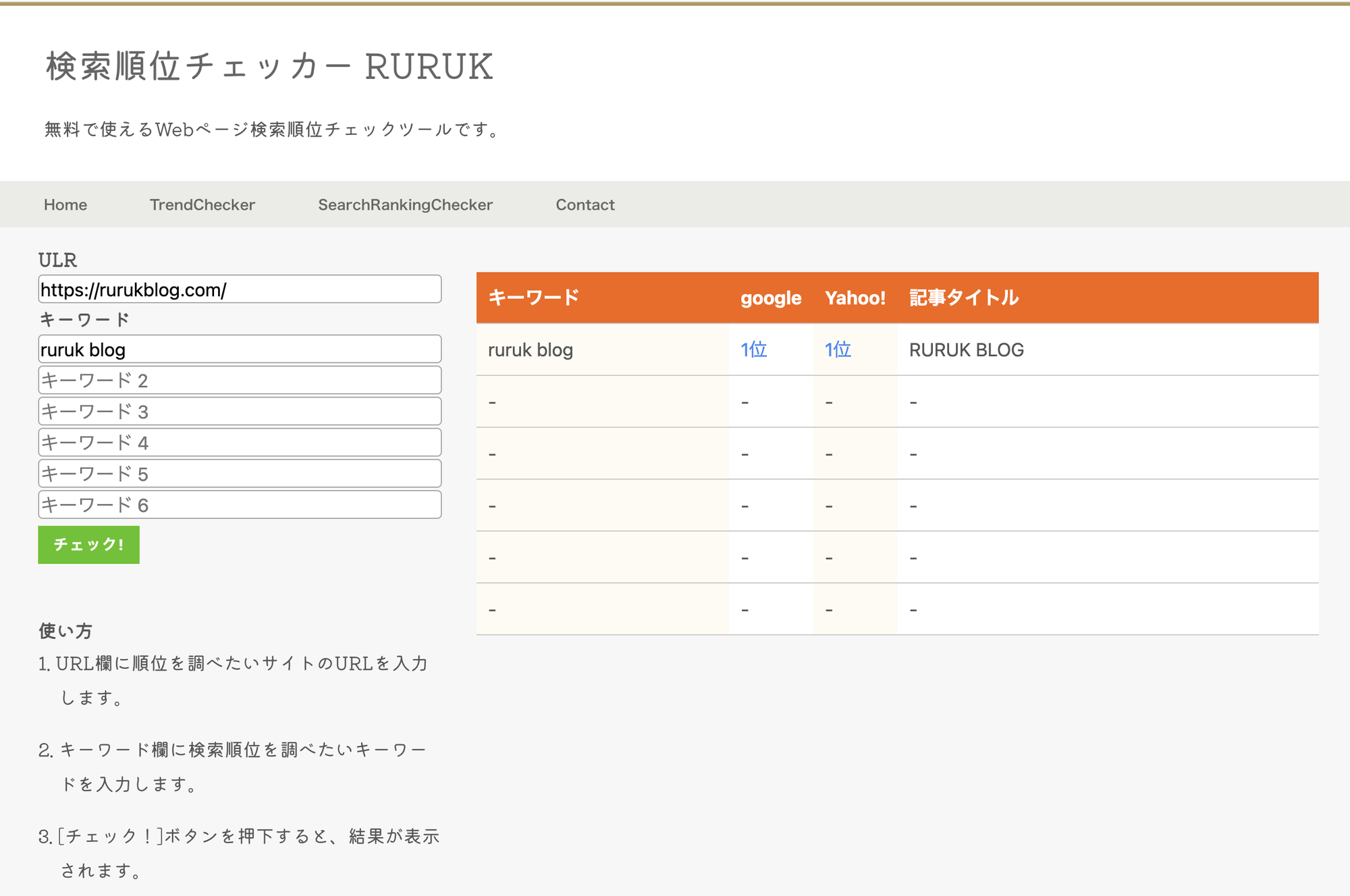
こちらもこのブログに実装しています。
GoogleからWebスクレイピングを行う方法についてはこちらの記事にまとめていますので、ご興味がある方は参考になるかと思います。
【Webスクレイピング入門】Google検索の上位サイトを件数指定して表示する方法
トレンドを観察するツールでできること
機能としては、各Webサービスから最新の人気記事や総合ランキングを読み込むといったものです。
読み込んでいるサイトは次の通りです。
・日経クロストレンド
・TechCrunch Japan
・Code Zine
・みんなの株式
・オーディオブック(audiobook.jp)
上記サイトは試験的にWebスクレイピングを行っているサイトです。
読み込むサイトをカスタマイズすることで、自分好みのサイトの記事一覧を表示することができます。
これにより、いちいちWebサイトを巡回することなく、効率良く情報収取を行うことができます。
おすすめ記事の内容が高頻度で変わるサイトをたくさん組み込むと、さらに面白いツールになりそうだなと考えています。(絶賛改修中!)
当サイトに組み込んでいますので、ご興味のある方は是非ご覧になってください!
https://rurukblog.com/trend-check
スクレイピングソース例
ツールのソースは単純かつパターンが少ないので、慣れてしまえば簡単に色々なサイトからスクレイピングが行えます。
以下の例では日経クロストレンドの最新人気記事を10件スクレイピングするソースです。
import requests
from bs4 import BeautifulSoup
import re
class NikkeiTrendyRankGet:
@staticmethod
def today_rank_get():
# 対象ページの情報を取得する
URL = "https://xtrend.nikkei.com"
rest = requests.get(URL)
# BeautifulSoupに記事内容を読み込ませる
soup = BeautifulSoup(rest.text, "html.parser", from_encoding="utf-8")
# Classに favorite-ranking が含まれるものを抽出する。
data_list = soup.find_all(class_=re.compile(
"section-tab-cnt-item js-tab-cnt is-active"))
data_list = data_list[0].find_all(class_="ranking-list-item")
#print(data_list)
ranking_number = 0
ranking_data_list = []
# ranking_key_list = {}
# 情報をループで取得し、リストで格納する。
for data in data_list:
# ニュースのタイトルを取得する
news_title = data.find_all(class_=re.compile("ranking-panel-title"))
ranking_number += 1
# ニュースへのリンクを取得する
news_link = data.find('a')
news_link = news_link['href']
ranking_data_key = {}
ranking_data_key['title'] = news_title[0].get_text()
ranking_data_key['url'] = URL + news_link
ranking_data_key['rank'] = ranking_number
ranking_data_list.append(ranking_data_key)
if ranking_number > 9:
break
return ranking_data_list
# 実行結果の確認
print(NikkeiTrendyRankGet.today_rank_get())
ソースの戻り値を配列 + 辞書型としているのは、Djangoのテンプレートにスクレイピングの情報を渡せるようにするためです。
テンプレートとはDjangoやFlaskなどで使用するhtmlファイルのことです。
View(スクレイピングなどの処理をするところ)からテンプレートに情報を渡すには辞書型にする必要があります。
その他のコードの解説については、後述します。
実行結果
以下が実行結果です。
※表示例は見やすように、著者が適度に改行を入れています。
[{'rank': 1, 'title': 'ユニクロ、H&Mと有名デザイナーのコラボは「愛用品」になるか',
'url': 'https://xtrend.nikkei.com/atcl/contents/18/00359/00015/?i_cid=nbpnxr_ranking'},
{'rank': 2, 'title': 'ホンダ「N-ONE」異色のリニューアル戦略\u3000外観同じでも顧客拡大',
'url': 'https://xtrend.nikkei.com/atcl/contents/18/00316/00058/?i_cid=nbpnxr_ranking'},
{'rank': 3, 'title': '「市場調査は意味がない」 スノーピーク会長、モノ作りの核心', '
url': 'https://xtrend.nikkei.com/atcl/contents/18/00449/00001/?i_cid=nbpnxr_ranking'},
{'rank': 4, 'title': 'コカ・コーラ、自販機サブスクを4月12日開始\u3000先着10万人対象',
'url': 'https://xtrend.nikkei.com/atcl/contents/watch/00013/01400/?i_cid=nbpnxr_ranking'},
{'rank': 5, 'title': '韓流コスメの次は「タイコスメ」\u3000Z世代が爆買いする3つのワケ',
'url': 'https://xtrend.nikkei.com/atcl/contents/18/00019/00030/?i_cid=nbpnxr_ranking'},
{'rank': 6, 'title': 'ソニーの「着るクーラー」が進化\u3000専用下着がなくても装着可能に',
'url': 'https://xtrend.nikkei.com/atcl/contents/18/00290/00037/?i_cid=nbpnxr_ranking'},
{'rank': 7, 'title': 'サントリー流「ブームのつくり方」\u3000三位一体戦略が勝ちパターン',
'url': 'https://xtrend.nikkei.com/atcl/contents/18/00442/00007/?i_cid=nbpnxr_ranking'},
{'rank': 8, 'title': '21年のマーケ・消費・技術トレンドは?\u3000全85キーワード指標調査',
'url': 'https://xtrend.nikkei.com/atcl/contents/casestudy/00012/00571/?i_cid=nbpnxr_ranking'},
{'rank': 9, 'title': '「お気に入りの服」調査ランキング\u3000「しまむら」男女で人気上昇',
'url': 'https://xtrend.nikkei.com/atcl/contents/research/00003/00036/?i_cid=nbpnxr_ranking'},
{'rank': 10, 'title': '消費行動が丸分かり!\u3000必修ワード「オルタナティブデータ」とは',
'url': 'https://xtrend.nikkei.com/atcl/contents/18/00450/00001/?i_cid=nbpnxr_ranking'}]
ソースの軽い解説
1. requests
requests を使用して、日経クロストレンドのトップページを全て取得します。
URL = "https://xtrend.nikkei.com"
rest = requests.get(URL)
requestsとは、PythonでWebページの情報を取得するためのモジュールのことです。
(Webページの情報取得には urllib.request も使用できます)
requests.get(URL)と書くと、URLで指定したページを取得することができます。
2. BeautifulSoup
次にBeautifulSoupで取得した記事情報を解析します。
soup = BeautifulSoup(rest.text, "html.parser")
BeautifulSoupとは、HTML や XML からデータを抽出するためのライブラリのことです。
BeautifulSoup( htmlファイル , "html.parser") と記述することで、
htmlファイルをプログラムで扱えるようなデータ構造に変換することができます。
(参考1 : Beautiful Soup 4.2.0 Doc. パーサーの指定)
htmlファイルを解析するには、BeautifulSoupの第二引数に"html.parser"を指定します。
ちなみに、rest.text のtextはサーバーから受信したhtmlファイルの中身を確認することができるrequestsのメソッドです。
(参考2 : requests-docs-ja.readthedocs)
3. データの抽出
data_list = soup.find_all(class_=re.compile
("article article-summary-horizontal favorite-ranking"))
soup.find_all() でhtmlファイル内の classに「article article-summary-horizontal favorite-ranking」が含まれる行を抽出してdata_list に格納しています。
(参考 3 : Beautiful Soup 4.2.0 Doc. find-all)
なぜこの行を抽出するかというと、 このクラスに「日経クロストレンド」のランキング情報が集約されているからです。
以降の行のソースでは、 ニュースタイトルが含まれるクラスを追加で抽出しています。
news_title = data.find_all(class_=re.compile("article-title"))
この状態だと、まだ不要なタグが残っているので、次の処理を行うとテキスト情報だけを抽出できます。
ちなみに、data.find_all()はリスト型で値が返ってきます。
ranking_data_key['title'] = news_title[0].get_text()
こうすると、[ユニクロ、H&Mと有名デザイナーのコラボは「愛用品」になるか]などの記事タイトル部分が抽出できます。
また、次のように書くと、BeautifulSoupで取得したaタグの中のhref属性の情報を抽出できます。
つまり、URLの情報が取得できます。
news_link = data.find('a')
news_link = news_link['href']
Djangoを試す
GUIで開発を行ってみたいという方については、Django用のコンテナを利用することで手軽に環境構築を行うことができます。(DockerとDocker Composeがインストール済であることが前提です)
GUIでのWebスクレイピング開発に挑戦してみたいという方はこちらをお試しください。
【Docker Compose】 Nginx - Django - MySQl の検証環境を作成
関連記事
【Webスクレイピング入門】ヤフーニュース の見出しとURLを取得する方法
【Python】Webスクレイピングの処理速度を高速化する方法